Data Analytics [DA] and Machine Learning [ML] are structured, quantitative approaches to answering difficult questions about datasets. The promise of DA and ML is that the insights gained about the world can be much more complex than those which can be found by humans, and also that those insights will be free of human bias. This essay will focus on the second promise, the total objectivity of DA/ML. It has long been recognized that the outcomes of DA/ML can vary significantly depending on the choice of methodology, which already strikes a blow to the claims of objectivity. However, lately a more fundamental problem has emerged — the data used for DA/ML often contains human biases and DA/ML performed on such data replicates them.

The subjective nature of data is potentially more troublesome than the subjective nature of methodological choices — different methods can easily be benchmarked against each other, but it is very hard to detect and treat subjectivity within the dataset. For example when estimating an individual’s ability to repay a loan using DA/ML techniques, we will very likely be using a dataset that consists of such judgements made historically by people. Unfortunately, some of those people were likely favouring some demographic groups and were biased against others. Therefore, the outcomes of the DA/ML analysis will be true to the dataset and replicate this bias. This sad phenomenon has been documented across many different characteristics (e.g. race, gender, age) and domains (e.g. lending, hiring, criminal justice, medical diagnosis). How would you spot the subjectivity in such a dataset when all you have is a list of the people that were granted loans?
For instance, it has been widely documented that it is harder for African-Americans to obtain loans even when their repayment ability matches exactly that of a White-American that has been awarded a loan [1]. This is a clear example of racism. When performing DA/ML we are training our models to perform the task according to the data we feed it. If we use a dataset coming from a racist lender we will find that the DA/ML we perform will replicate such racism as that is the data it receives during learning. It should come as little surprise that when we analyse racist judgements we arrive at racist conclusions.
A more subtle and complex example is when we do not train to estimate human judgements (e.g. whether or not to award a loan), but rather real-world outcomes (e.g. loan repayment/default). Counter-intuitively, this case too can lead to discrimination. Such discrimination happens through “vicious feedback loops” [2]. For instance, when a person is judged to be a more risky borrower their interest will be set to a higher level. In a given time this increases the sum that they must pay back, therefore making them more likely to default on the loan. This acts as positive feedback to the DA/ML model, even though the same person may not have defaulted if they were judged lower risk in the first place and had their interest set accordingly. This person may have been judged to be more risky based on a characteristic such as race, gender or postcode. Therefore DA/ML is not safe from bias even when data used to train the models are objectively measured outcomes, as opposed to subjective decisions of possibly biased people.
A number of approaches have been devised to counter these issues. Here I will focus on the most popular one that also happens to be the worst at actually addressing the bias. This approach involves simply removing the column of the data containing the characteristic that we wish the outcome of our DA/ML to not be biased against. The reason why this doesn’t work is simple: the information about any characteristic of an individual is to some degree contained in the other characteristics about the individual. For instance, Amazon’s experimental hiring algorithm with no access to information about the applicant’s gender learned to reject applicants from certain female-only colleges [3]. The same thing happened with the Apple card recently, when it was found to offer smaller amounts of credit to women than men with otherwise similar backgrounds [4]. Let’s see an example of how this happens in greater detail.
In this example we will focus on ageist discrimination that can emerge as a result of analysing which employees have more absences from work. This example is loosely based on analysis that we recently performed at illumr, please see the original report [5] for details. When you try to create a model of employee absences with a dataset that contains information relating to age, the result of your DA/ML will be a model that almost entirely relies on age in determining how many absences an employee will incur. As age is one of the protected characteristics according to the EU convention on human rights and US equality act, using age as a criterion during hiring in this way is clearly illegal.
When you take the age out of your dataset and do the same exercise you will arrive at almost exactly the same results. This happens because your model has implicitly identified the age of employees even though it has never seen it. The reason for this is that the information about one’s age is contained in the other information the employer holds. This information is not held explicitly, rather there are weak indicators, also called proxy variables. In the (entirely fictional) example below you can see that all first name, address, education, smoking and drinking habits, pet ownership, diet, height and BMI are all proxy variables for age.
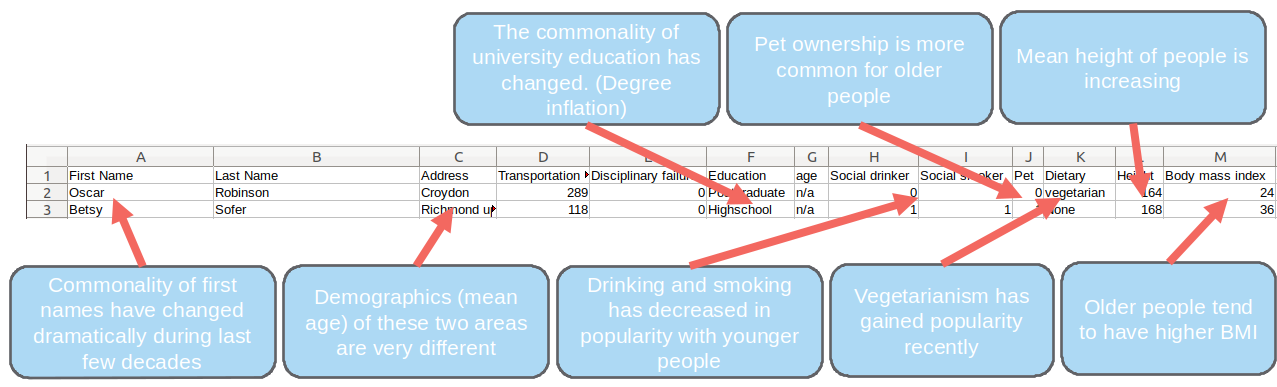
DA/ML will in this example infer age for each individual and then use that as a strong indicator for the number of absences without the age being explicitly used by the model. Proxy variables can be complex and therefore hard to spot, so what is the solution?
One solution is to explicitly look for discrimination in the output of your model and then post-hoc correct for it. This however has a number of problems (that I discuss in depth in my paper [6]). Most notably there is no quantitatively defined and universally accepted notion of discrimination, with some definitions even being mutually exclusive [7]. At illumr we have developed a Generative AI solution, called Rosa, that takes an alternative approach. Rosa takes your dataset and looks for the proxy variables, then changes them as little as needed to remove the information about the protected characteristics. When you use your DA/ML on the data processed with Rosa, there are no proxy variables and there is therefore no possibility for your model to discriminate. You can find out more and try Rosa for free (with some minimal limitations) at https://illumr.com/debias-data-solution/.
References:
[1] Margery Austin Turner. Mortgage lending discrimination: A re-view of existing evidence. 1999.
[2] Cathy O’Neil.Weapons of math destruction: How big data in-creases inequality and threatens democracy. Broadway Books, 2016.
[3] https://www.reuters.com/article/us-amazon-com-jobs-automation-insight/amazon-scraps-secret-ai-recruiting-tool-that-showed-bias-against-women-idUSKCN1MK08G, retrieved 1st February 2020.
[4] https://www.wired.com/story/the-apple-card-didnt-see-genderand-thats-the-problem/, retrieved 1st February 2020.
[5] Demonstrating Rosa: The fairness solution for any Data Analytic pipeline
[6] Rosa's Novel Technology: A step beyond Generative AI we call Fair Adversarial Networks
[7] Alexandra Chouldechova. Fair prediction with disparate impact:A study of bias in recidivism prediction instruments.Big data,5(2):153–163, 2017.